概要
Kafka学习笔记–存储内部(MD版)。
博客
原帖收藏于IT老兵驿站
前言
研究一下 Kafka 的存储内部的原理,这里转发一篇文章,个人感觉这篇文章讲的非常好,所以推荐出来,同时做一下学习笔记。
当然,基于不鼓励懒人,启发式记录的原则,我只是对一些重点进行笔记记录,这样无论是将来自己看,还是现在别人看,都需要参考笔记去阅读一下原文—-这也才是笔记的意义。
正文
A Practical Introduction to Kafka Storage Internals
Kafka is everywhere these days. With the advent of Microservices and distributed computing, Kafka has become a regular occurrence in every product architecture. In this article, I’ll try to explain how Kafka’s internal storage mechanism works.
Since this is going to be a deep dive into Kafka’s internals, I would expect you to have some understanding about it. Although I’ve tried to keep the entry level for this article pretty low, you might not be able to understand everything if you’re not familiar with the general workings of Kafka. Proceed further with that in mind.
Kafka is usually referred to as a Distributed, Replicated Messaging Queue, which is technically true but might lead to some confusion, depending on your definition of what a messaging queue is. Instead, I prefer the definition Distributed, Replicated Commit Log. This I think clearly represents what Kafka does as all of us understand how logs are written to disk. And in this case, it is the messages pushed into Kafka that are stored to disk.
这里是一些总体的概要介绍。
Kafka 通常被引用为一个分布的,有备份的消息队列,这在技术上是正确的,但是这个会带来一些困扰,取决于你对于消息队列的定义。取而代之的,作者更倾向于这样的定义,Kafka 是一个分布的,备份的提交日志(commit log,这个是一个有语义的术语)。
Kafka 自己定位自己是一个分布式的流化平台,而不是上面所写的分布式,复制的消息队列,或者分布式的,复制的提交日志。(这里这个流化平台的概念不是太容易理解。)
With reference to storage in Kafka, you’ll always hear two terms, Partition and Topic. Partitions are the unit of storage in Kafka for data messages. And Topic can be thought of as being a container in which these partitions lie.
With the basic stuff out of our way, let’s understand these concepts better by working with Kafka.
I am going to start by creating a topic in Kafka with three partitions defined. If you want to follow along, the command looks like this for a local Kafka setup on windows.
而关于 Kafka 的存储的介绍,我们会经常听到两个术语,Partition 和 Topic。Partitions 是 Kafka用来存储数据消息的基本单元,一个 Topic 可以被认为是这些 partition 的容器。
下面,作者会带着大家来实践一把。(下面的这些命令是运行在 windows 平台上的,而想要运行在其他的平台,可以参考《快速开始》那一章节。)
kafka-topics.bat --create --topic freblogg --partitions 3 --replication-factor 1 --zookeeper localhost:2181
按照上面的命令,启动一下 Kafka。
If I go to Kafka’s log directory, I see three directories created as follows.
$ tree freblogg*
freblogg-0
|-- 00000000000000000000.index
|-- 00000000000000000000.log
|-- 00000000000000000000.timeindex
`-- leader-epoch-checkpoint
freblogg-1
|-- 00000000000000000000.index
|-- 00000000000000000000.log
|-- 00000000000000000000.timeindex
`-- leader-epoch-checkpoint
freblogg-2
|-- 00000000000000000000.index
|-- 00000000000000000000.log
|-- 00000000000000000000.timeindex
`-- leader-epoch-checkpoint
上面的例子创建了3个 partition,当你查看目录,会看到上文这样的目录和文件结构。
We have three directories created because we’ve given three partitions for our topic, which means that each partition gets a directory on the file system. You also see some files like index, log etc. We’ll get to them shortly.
一个 partition 对应着一个实际的目录,有几种文件,index,log 等等。别着急,下面会有讲解。
这句是关键,一个 partition 对应着一个目录。
One more thing that you should be able to see from here is that in Kafka, the topic is more of a logical grouping than anything else and that the Partition is the actual unit of storage in Kafka. Let’s understand partitions in some more detail.
Partitions
A partition, in theory, can be described as an immutable collection (or sequence) of messages. We can only append messages to a partition but cannot delete from it. And by “We”, I am talking about the Kafka consumer. A consumer can’t delete the messages in the topic.
Now we’ll send some messages into the topic. But before that, I want you to see the sizes of files in our partition folders.
这里你可以看到,一个 topic 其实是一个逻辑上的组,而 partition 则是 Kafka 中实际的存储单元。
一个 partition,在理论上,被描述为一个不可修改的消息集合(或者序列)。我们仅仅可以给一个 partition 追加消息而不能从它中间删除。这里的“我们”,我是说作为一个Kafka消费者(consumer)。
在发送消息给这个主题之前,我们先看一下这些文件的大小。
$ ls -lh freblogg-0
total 20M
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
- freblogg 197121 0 Aug 5 08:26 00000000000000000000.log
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
- freblogg 197121 0 Aug 5 08:26 leader-epoch-checkpoint
You see the index files combined are about 20M in size while the log file is completely empty. This is the same case with freblogg-1 and freblogg-2folders.
Now let us send a couple of messages and see what happens. To send the messages I’m using the console producer as follows:
2个 index 文件大概 20M,log 文件是空的,3个目录是一样的。
现在,我们发送一些消息去看看会发生什么。
1 | kafka-console-producer.bat --topic freblogg --broker-list localhost:9092 |
I have sent two messages, first a customary “hello world” and then I pressed the Enter key, which becomes the second message. Now if I print the sizes again:
笔者发送了两个消息,第一个是“hello world”,第二个是一个空消息。
$ ls -lh freblogg*
freblogg-0:
total 20M
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
- freblogg 197121 0 Aug 5 08:26 00000000000000000000.log
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
- freblogg 197121 0 Aug 5 08:26 leader-epoch-checkpoint
freblogg-1:
total 21M
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
- freblogg 197121 68 Aug 5 10:15 00000000000000000000.log
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
- freblogg 197121 11 Aug 5 10:15 leader-epoch-checkpoint
freblogg-2:
total 21M
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
- freblogg 197121 79 Aug 5 09:59 00000000000000000000.log
- freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
- freblogg 197121 11 Aug 5 09:59 leader-epoch-checkpoint
You will see that the log files have a non zero size now. This is because the messages in the partition are stored in the ‘xxxx.log’ file. To confirm that the messages are indeed stored in the log file, we can just see what’s inside that log file.
可以看到两个文件发生了变化,都是 log 文件,这是因为partition的消息是存储在 log 文件里面的,我们来再确认一下。
$ cat freblogg-2/*.log
@^@^B°£æÃ^@^K^Xÿÿÿÿÿÿ^@^@^@^A"^@^@^A^VHello World^@
The file format of the ‘log’ file is not one that is conducive for textual representation but nevertheless, you should see the ‘Hello World’ at the end indicating that this file got updated when we have sent the message into the topic.
Notice that the first message we sent, went into the third partition (freblogg-2) and the second message went into the second partition. This is because Kafka arbitrarily picks the partition for the first message and then distributes the messages to partitions in a round robin fashion. If a third message comes now, it would go into freblogg-0 and this order of partition continues for any new message that comes in. We can also make Kafka always choose the partition for our messages by adding a key to the message. Kafka stores all the messages with the same key into a single partition.
Each new message in the partition gets an ID which is one more than the previous Id number. This Id number is also called as the Offset. So, the first message is at ‘offset’ 0, the second message is at offset 1 and so on. These offset Id’s are always incremented from the previous value.
我们可以看到这个 log 文件的尾部有 “Hello World”,这说明这个消息被发送到了这个 topic 中。
注意,第一个消息发到了第三个 partition,第二个消息发送到了第二个 partition。这是因为Kafka 是随机地选取了一个 partition 来发送第一个消息,然后使用一个 round robin 的方式选择第二个 partition 来发送第二个消息,如果有第三个消息,它就会发送到第一个 partition 里面。我们也可以选择 partition 来发送,通过增加一个 key 给消息,Kafka 的一个 partition 是使用同一个 key 的。
这里讲的在每个 partition 里面,有一个 sequence Id,也就是 offset,每个消息一个,按1来步进增加。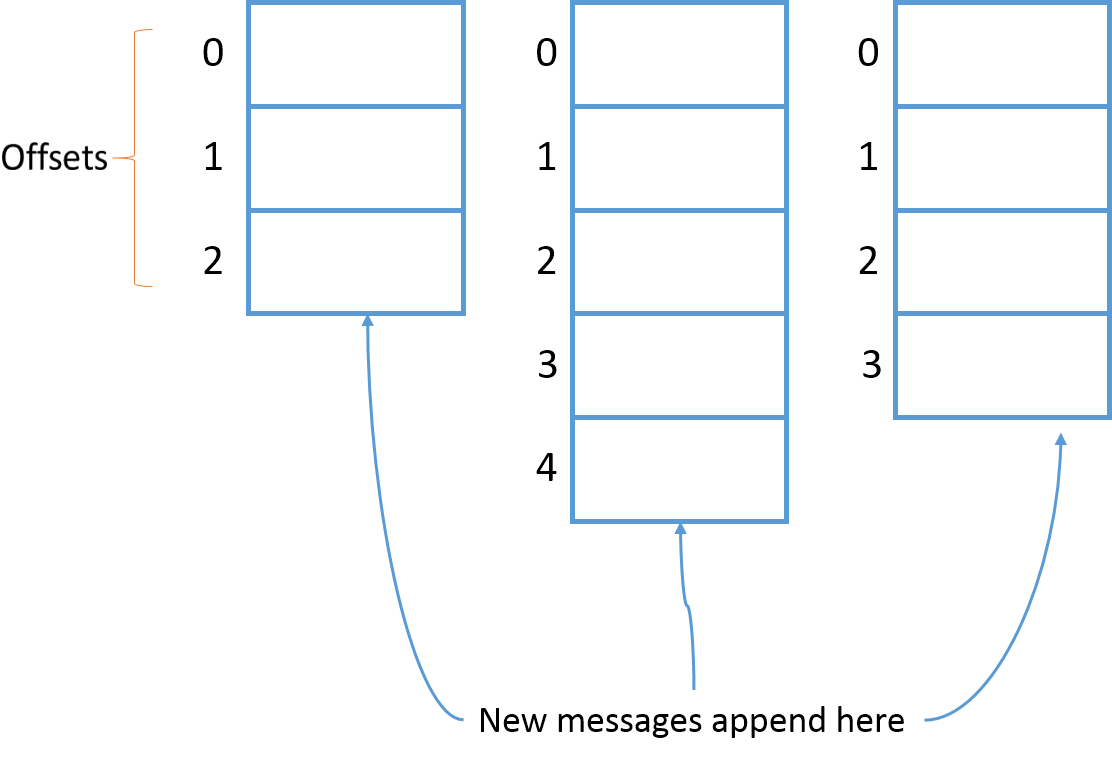
<Quick detour>
We can understand those random characters in the log file, using a Kafka tool. Those extra characters might not seem useful to us, but they are useful for Kafka as they are the metadata for each message in the queue. If I run,
1 | kafka-run-class.bat kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files logs\freblogg-2\00000000000000000000.log |
This gives the output
Dumping logs\freblogg-2\00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 CreateTime: 1533443377944 isvalid: true keysize: -1 valuesize: 11 producerId: -1 headerKeys: [] payload: Hello World
offset: 1 position: 79 CreateTime: 1533462689974 isvalid: true keysize: -1 valuesize: 6 producerId: -1 headerKeys: [] payload: amazon
(I’ve removed a couple of things from this output which are not necessary for this discussion.)
我们用 Kafka 的工具来输出一下log里面的内容,这些是一些元数据。
You can see that it stores information of the offset, time of creation, key and value sizes etc along with the actual message payload in the log file.
</Quick detour>
It is also important to note that a partition is tied to a broker. In other words, If we have three brokers and if the folder freblogg-0 exists on broker-1, you can be sure that it will not appear in any of the other brokers. Partitions of a topic can be spread out to multiple brokers but a partition is always present on one single Kafka broker (When the replication factor has its default value, which is 1. Replication is mentioned further below).
partition 是和 broker 绑定在一起的,一个 partition 只会在一个 broker 上出现一次。这里的broker 指的是宿主服务器。
但是如何备份呢?按照之前几篇文章的介绍,每个 partition 会在每个 broker 上被备份一份。
Segments
We’ll finally talk about those index and log files we’ve seen in the partition directory. Partition might be the standard unit of storage in Kafka, but it is not the lowest level of abstraction provided. Each partition is sub-divided into segments.
这里提到了一个新的概念,segments,尽管 partition 被作为一个标准的存储单元,但并不是被提供的最低级别的抽象。每一个 partition 又被划分为 segments。
A segment is simply a collection of messages of a partition. Instead of storing all the messages of a partition in a single file (think of the log file analogy again), Kafka splits them into chunks called segments. Doing this provides several advantages. Divide and Conquer FTW!
一个 segment是在一个 partition 里面的一个简单的消息集合。取代把一个 partition 的所有消息都放在一个单一文件里面的方案是,Kafka 把它们分成被称为 segment 的大块。这是一种分而治之的方法。
Most importantly, it makes purging data easy. As previously introduced partition is immutable from a consumer perspective. But Kafka can still remove the messages based on the “Retention policy” of the topic. Deleting segments is much simpler than deleting things from a single file, especially when a producer might be pushing data into it.
很重要的是,这使得清理数据非常容易。Kafka 根据 topic 上的 “Retention policy”(保留策略)来移除消息。这样,删除一个 segment 会比从一个文件中删除东西要容易的多,尤其在一个producer 可能要往里面放数据的时候。
1 | $ ls -lh freblogg-0 |
The
00000000000000000000in front of the log and the index files in each partition folder, is the name of our segment. Each segment file has segment.log, segment.index and segment.timeindex files.
在每个 index 文件前面的00000000000000000000,是 segment 的名字,每个 segment 由segment.log,segment.index 和 segment.timeindex 构成。
Kafka always writes the messages into these segment files under a partition. There is always an active segment to which Kafka writes to. Once the segment’s size limit is reached, a new segment file is created and that becomes the newly active segment.
会有一个活跃的 segment 来让Kafka去写入。一旦segment的大小限制达到了,一个新的segment文件会被创建,并且成为新的活跃的 segment。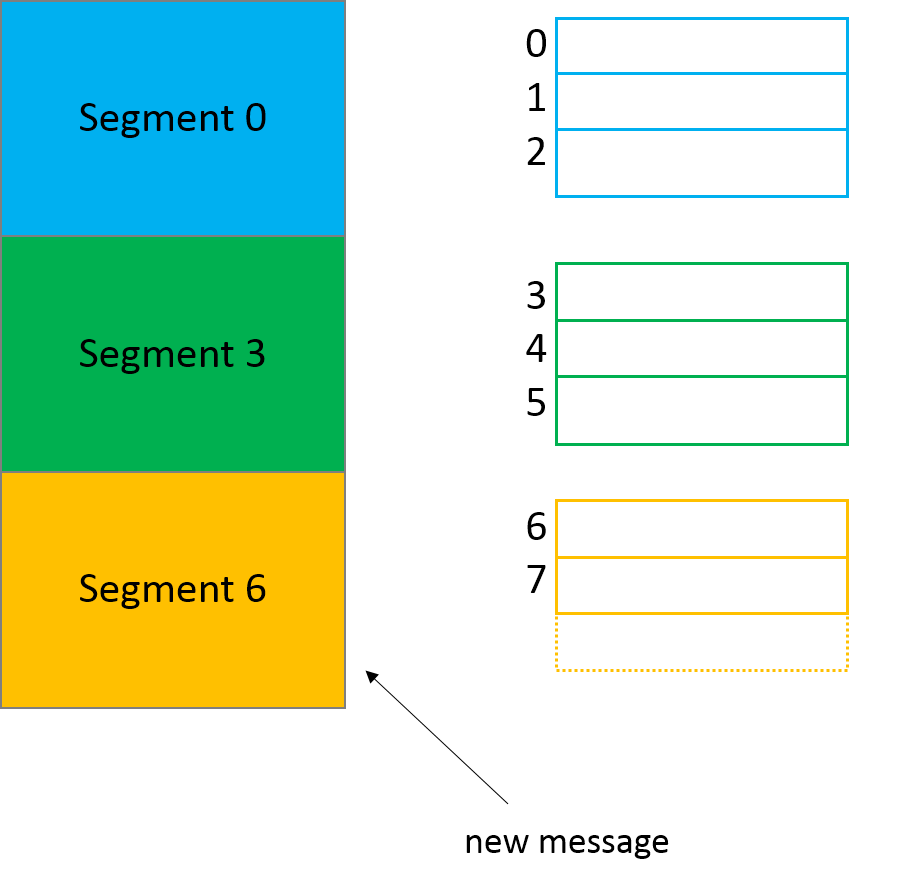
Each segment file is created with the offset of the first message as its file name. So, In the above picture, segment 0 has messages from offset 0 to offset 2, segment 3 has messages from offset 3 to 5 and so on. Segment 6 which is the last segment is the active segment.
每个 segment 被使用第一个消息的 offset 来作为它的文件名来创建,(可以看上面的图,我第一次看到这个图,还对这个segment的名字感到奇怪)。
1 | $ ls -lh freblogg* |
In our case, we only had one segment in each of our partitions which is 00000000000000000000. Since we don’t see another segment file present, it means that 00000000000000000000 is the active segment in each of those partitions.
The default value for segment size is a high value (1 GB) but let’s say we’ve tweaked Kafka configuration so that each segment can hold only three messages. Let’s see how that would play out.
每个 segment 的默认大小是1GB,但是让我们调整一下 Kafka 的配置,让每个 segment 只能保有3条消息。
Say this is the current state of the freblogg-2 partition. We’ve three messages pushed into it.
Since ‘three messages’ is the limit we’ve set, If a new message comes into this partition, Kafka will automatically close the current segment, create a new segment, make that the active segment and store that new message in the new segment’s log file.
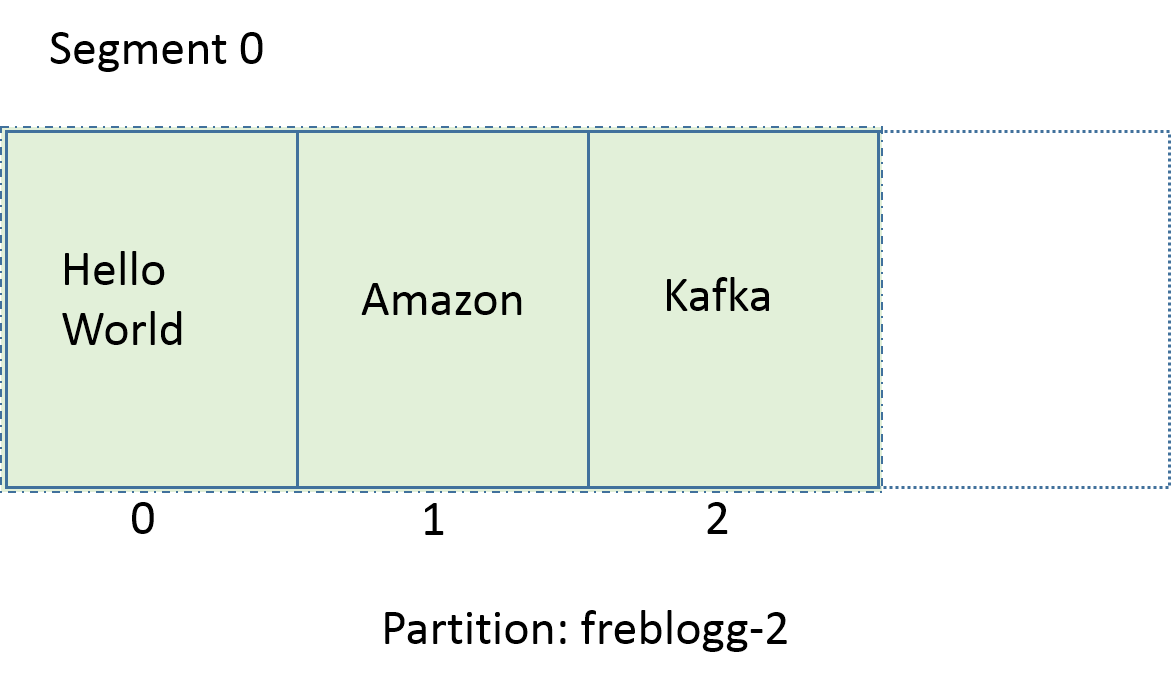
因为我们设置了3条消息的显示,所以如果有新的消息到来,Kafka 将会自动关闭当前的segment,创建一个新的 segment,让它成为活跃的 segment,并且在新的 segment 里面存储新的消息。
(I’m not showing the preceding zeroes to make it easy on the eyes)
1 | freblogg-2 |
You should’ve noted that the name of the newer segment is not 01. Instead, you see 03.index, 03.log. So, what is going on?
看到了吧,新的 segment 出现了,名字是03。
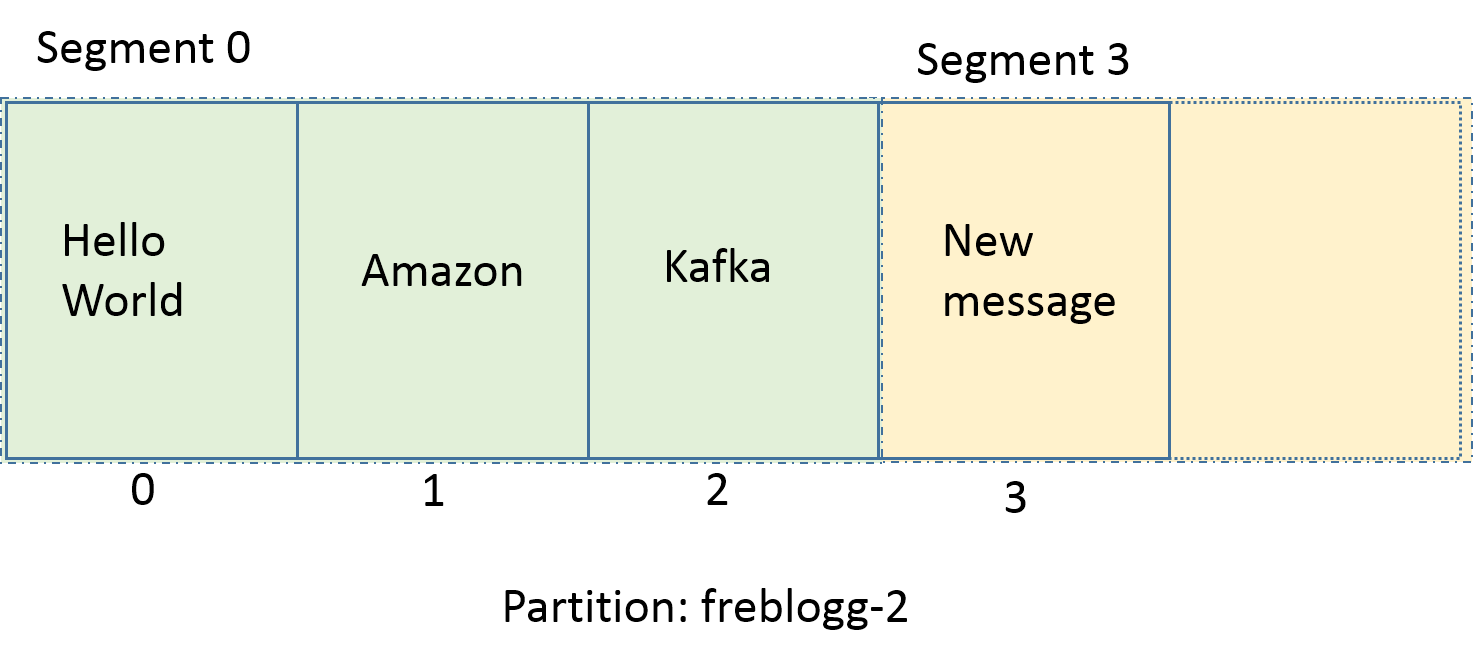
This is because Kafka makes the lowest offset in the segment as its name. Since the new message that came into the partition has the offset 3, that is the name Kafka gives for the new segment. It also means that since we have 00 and 03 as our segments, we can be sure that the messages with offsets 0,1 and 2 are indeed present in the 00 segment. New messages coming into freblogg-2 partition with offsets 3,4 and 5 will be stored in the segment 03.
One of the common operations in Kafka is to read the message at a particular offset. For this, if it has to go to the log file to find the offset, it becomes an expensive task especially because the log file can grow to huge sizes (Default — 1G). This is where the .index file becomes useful. Index file stores the offsets and physical position of the message in the log file.
因为 segment 可以达到1G,那么查找起来,有一个索引会快很多,Index 文件存储着 offsets 和消息在 log 文件上的物理位置。
An index file for the log file I’ve showed in the ‘Quick detour’ above would look something like this:

而 index 文件则会显示类似上面的内容,在1G的空间内,有一个索引来指定位置,这样查找起来会非常的块。
If you need to read the message at offset 1, you first search for it in the index file and figure out that the message is in position 79. Then you directly go to position 79 in the log file and start reading. This makes it quite effective as you can use binary search to quickly get to the correct offset in the already sorted index file.
Parallelism with Partitions
To guarantee the order of reading messages from a partition, Kafka restricts to having only consumer (from a consumer group) per partition. So, if a partition gets messages a,f and k, the consumer will also read them in the order a,f and k. This is an important thing to make a note of as order of message consumption is not guaranteed at a topic level when you have multiple partitions.
消息的顺序仅在 partition 层面被保证,在 topic 层面是不被保证的。
Just increasing the number of consumers won’t increase the parallelism. You need to scale your partitions accordingly. To read data from a topic in parallel with two consumers, you create two partitions so that each consumer can read from its own partition. Also since partitions of a topic can be on different brokers, two consumers of a topic can read the data from two different brokers.
仅仅增加 consumer 的数量并不能增加并行能力,增加 partition 才可以,不同的 partition 有可能位于不同的 broker上,这样增加了数据的读的能力。
Topics
We’ve finally come to what a topic is. We’ve covered a lot of things about topics already. The most important thing to know is that a Topic is merely a logical grouping of several partitions.
一个 Topic 只不过是一些 partition 的一个逻辑上的组。
A topic can be distributed across multiple brokers. This is done using the partitions. But a partition still needs to be on a single broker. Each topic will have its unique name and the partitions will be named from that.
Replication
Let’s talk about replication. Whenever we’re creating a topic in Kafka, we need to specify what the replication factor we need for that topic. Let’s say we’ve two brokers and so we’ve given the replication-factor as 2. What this means is that Kafka will try to always ensure that each partition of this topic has a backup/replica. The way Kafka distributes the partitions is quite similar to how HDFS distributes its data blocks across nodes.
Say for the freblogg topic that we’ve been using so far, we’ve given the replication factor as 2. The resulting distribution of its three partitions will look something like this.
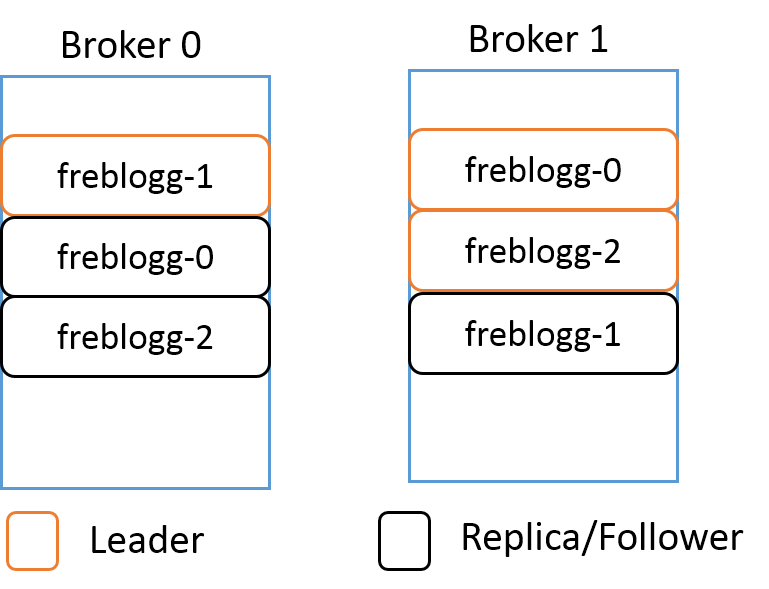
Even when you have a replicated partition on a different broker, Kafka wouldn’t let you read from it because in each replicated set of partitions, there is a LEADER and the rest of them are just mere FOLLOWERS serving as backup. The followers keep on syncing the data from the leader partition periodically, waiting for their chance to shine. When the leader goes down, one of the in-sync follower partitions is chosen as the new leader and now you can consume data from this partition.
你永远是从作为 LEADER 的 partition 中去读数据,其余的 FOLLOWERS 仅仅作为备份。”The followers keep on syncing the data from the leader partition periodically, waiting for their chance to shine. “这句话挺有意思,这些 follower 周期性地保持着对 leader 的 partition 的数据同步,等待着它们能够大放光芒的一天。
A Leader and a Follower of a single partition are never in a single broker. It should be quite obvious why that is so.
Finally, this long article ends. Congratulations on making this far. You now know most of what there is to know about Kafka’s data storage. To ensure that you retain this information let’s do a quick recap.
Recap
Data in Kafka is stored in topics
Topics are partitioned
Each partition is further divided into segments
Each segment has a log file to store the actual message and an index file to store the position of the messages in the log file
Various partitions of a topic can be on different brokers but a partition is always tied to a single broker
Replicated partitions are passive. You can consume messages from them only when the leader is down
That ought to cover everything we’ve talked about. Thanks for reading. See you again in the next one.
Attribution:
Kafka image — https://kafka.apache.org/images/kafka_diagram.png
总结
这篇文章写得很好,非常清楚地总体地讲明白了Kafka的存储,我初步翻译了一下,总体英文难度不高,其余的内容很容易看懂。
补充一点,在partition上面的目录结构,参考这里:

参考
https://medium.com/@durgaswaroop/a-practical-introduction-to-kafka-storage-internals-d5b544f6925f
https://stackoverflow.com/questions/27731558/where-kafka-stores-partitions-for-the-topics
修改历史
2019-11-13,修改了一下格式,每个英文单词前后加了空格,移除了一些原本的疑问,修正了几处错误,之前的图片链接都失效了,只好重新下载,再上传上去,学习就是辛苦的,苦中作乐吧。